PEEK: Give Your Agent an Orientation Cache
We introduce PEEK, a system that caches reusable orientation knowledge about a recurring external context as a small, prompt-resident context map.
13 minute read
Paper: https://arxiv.org/abs/2605.19932
Code: github.com/zhuohangu/peek
tl;dr
LLM agents such as Claude Code
PEEK fills this gap by caching a context map: a compact, constant-sized artifact that sits inside the agent’s prompt and stores what the agent has learned about the external context itself across interactions. The map is maintained by a programmable cache policy with three modules: a Distiller that extracts transferable knowledge from execution trajectories, a Cartographer that translates that knowledge into structured edits, and a priority-based Evictor that enforces a fixed token budget.
Across long-context tasks, PEEK improves quality while using fewer iterations and lower cost than strong baselines, including the state-of-the-art prompt-learning framework ACE

Prelude: A Cache Hiding in Plain Sight

Over the past 3–5 years, context management has become one of the most important areas of progress for large language model (LLM) systems. We have seen long context windows, retrieval, context compaction, context offloading, prompt learning (also called context engineering or context adaptation), memory management, and KV-cache management (systems work I worked on as an undergrad at UChicago/LMCache Lab and Tensormesh, where our team was among the first to optimize KV-cache reuse beyond GPU HBM for LLMs).
When I started my PhD at MIT last September, I found myself standing at a crossroads, unsure which way to go: had the AI community already exhausted every obvious axis of context management, or was there still a systems idea hiding in plain sight?
The setting that made the answer feel concrete was agentic workloads. Recent agents, whether general-purpose assistants or coding agents, increasingly operate over long and recurring external contexts: document corpora, code repositories, enterprise records, and other resources that the agent queries again and again. I believe this pattern will only become more common.
As a student who started doing CS research in a systems group, I suddenly realized that we might be missing one of the oldest tricks in computer science: a cache. Not a KV cache, and not just a vector database, but a genuine agent-side cache. The intuition is simple: give the language model (LM) a small portion of its context window, a little blurb that is never compacted away, is never externalized into environment storage, and can be revised over time.
Then the real question becomes: how do we decide what should go in that blurb?
Consider an enterprise analyst repeatedly querying 50,000+ user-feedback entries:
- Do users prefer feature A or feature B?
- What onboarding complaints appear most often?
- Which enterprise customers mention SSO problems?
- Are complaints concentrated in one product area?
The corpus stays mostly fixed, but the tasks change. A human analyst would not start each question from scratch. After a few passes, they might keep a lightweight table of contents, memos about key entities and constants, a record of which regions have been inspected, and records of common intermediate results. An agent facing the same setting needs an analogous aid: not the whole corpus in the prompt, and not just a memory of previous chat turns, but a small maintained view of the external context that helps it re-enter the same context more intelligently each time.
What Existing Context Management Misses
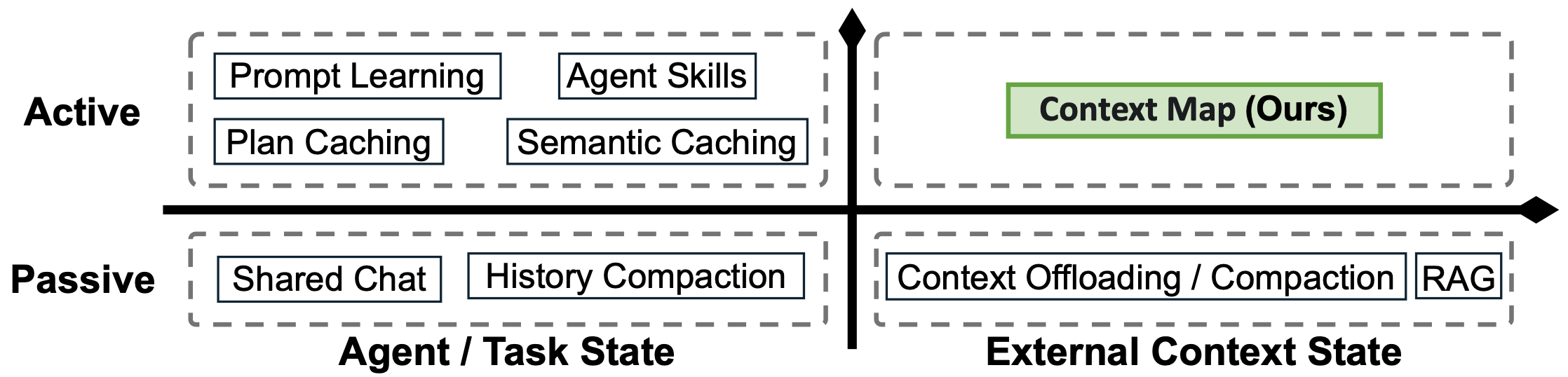
Modern agentic systems already manage long contexts in several useful ways, but each preserves a different kind of object, and none preserves what we argue is most needed for repeated same-context workloads:
- Shared chat carries prior trajectory, but it quickly becomes noisy and low-density.
- History compaction summarizes previous interactions, but it is not designed to preserve reusable knowledge about the external context.
- RAG, context offloading, and compaction
preserve access to raw or condensed material, but they do not maintain a curated artifact about the context itself. - Prompt learning
curates task-level strategies, not contextual knowledge about a recurring external context.
This leaves a missing quadrant: active external-context state. PEEK targets this quadrant by maintaining a small artifact that captures what has been learned about a recurring context and keeps it available to the agent.
Put differently, PEEK asks two questions: what belongs in a small prompt-resident context map, and how much does it help agentic systems when answering sequences of requests over a large shared corpus?
What Is a Context Map?
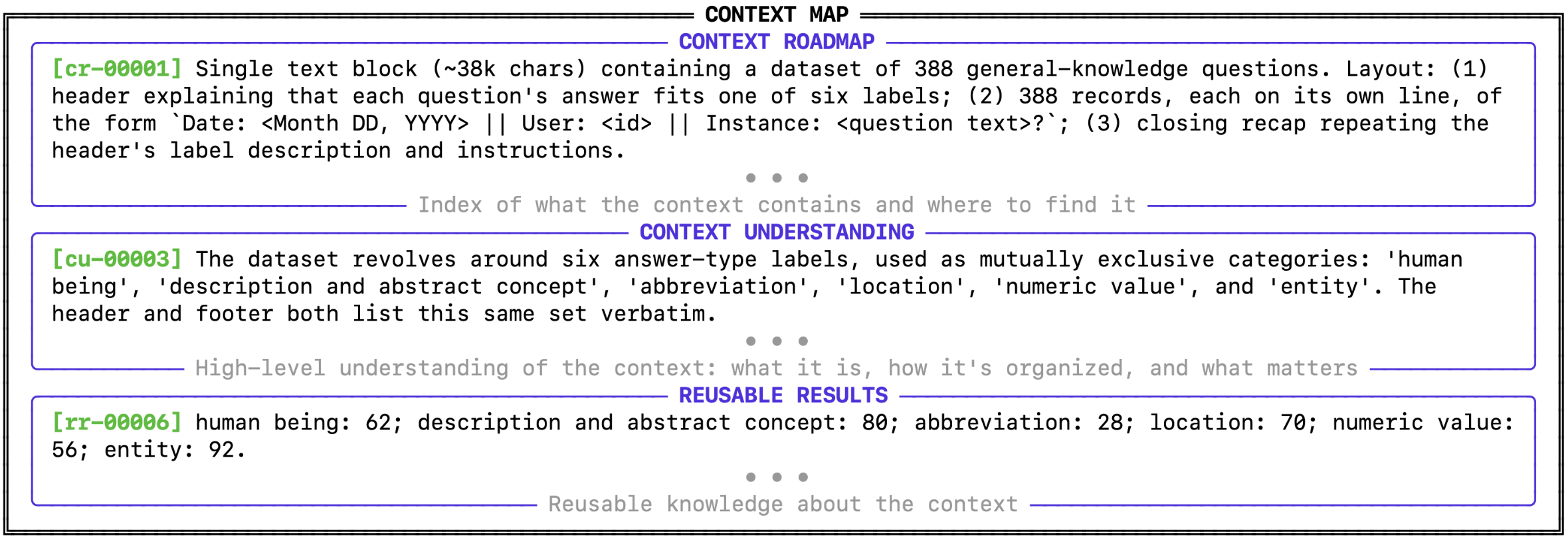
A context map is a small, constant-sized artifact inside the agent’s prompt that stores reusable orientation knowledge about an external context. It is not a summary of the current conversation, and it is not a task-level playbook. It is closer to the reusable map a human analyst would keep after several passes through a corpus: what the corpus contains, how it is organized, which constants or schemas matter, and where different kinds of evidence tend to appear.
The analogy is a cache in a computer system. Fast memory near the processor keeps useful data close at hand; a context map keeps useful contextual knowledge close to the language model. Unlike KV-cache management, which optimizes hidden token states inside the model, a context map is an agent-level semantic artifact. Its value comes from curated meaning, not reused activations.
The map persists across queries, is never compacted away, and is updated as the agent interacts with the external context. Figure 4 shows an example map produced by PEEK after one query.
How PEEK Works
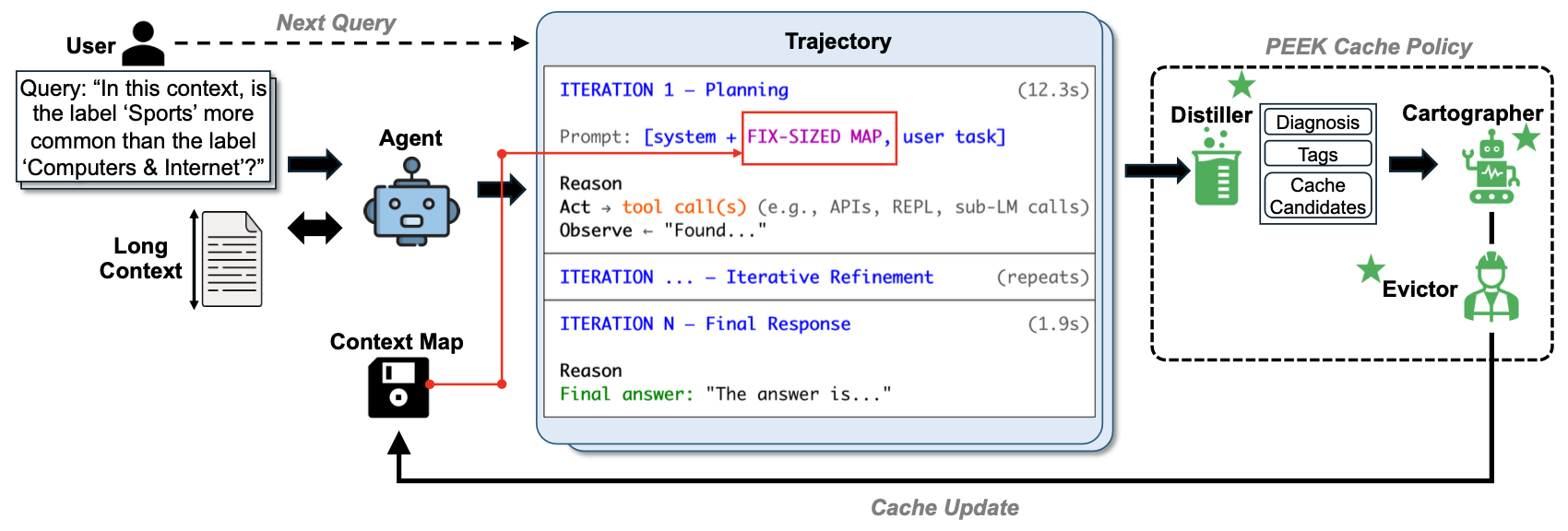
PEEK has two coupled mechanisms, shown in Figure 3. First, the current context map is placed in the agent’s system prompt (boxed in red). Second, after each query completes, a cache-management policy (dashed box, green stars) inspects the execution trajectory and updates the map for future queries.
The PEEK Algorithm (nested below; click to expand) runs an agent over a sequence of tasks on the same recurring external context $\mathcal{C}$. The current map is prepended to every run. PEEK can update it fully online, or freeze it after a small number of queries once enough orientation knowledge has been cached.
Each run produces an execution trajectory. PEEK updates the map through three modules:
- Distiller. Reads the trajectory and current map, then identifies reusable context knowledge, diagnoses how the agent spent its iterations, and tags existing map entries as helpful, harmful, neutral, or stale.
- Cartographer. Turns the Distiller output into structured edits: ADD, DELETE, or REPLACE. This keeps the map deduplicated and prevents task-specific details from leaking into the cache.
- Evictor. Enforces a fixed token budget $B$. If the map grows too large, it removes lower-scoring entries first, breaking ties by evicting older entries.
The PEEK Algorithm (click to expand)

Main Results
We evaluate PEEK on tasks where multiple queries share the same long context. The benchmarks cover two kinds of long-context demand: reasoning and aggregation over long inputs (OOLONG
PEEK consistently outperforms the baselines. On OOLONG, it beats ACE by +7.8 to +15.0%. On CL-bench, it improves over ACE by +6.0% solving rate and +9.9% rubric accuracy. These gains appear in both coarse and fine-grained metrics, suggesting that context maps improve task correctness by strengthening context understanding rather than overfitting to specific task types.
Cheaper, Faster, Better
PEEK also improves the cost-quality tradeoff. Figure 5 plots score against total iterations and total cost. Across benchmarks, PEEK consistently lies on the Pareto frontier.
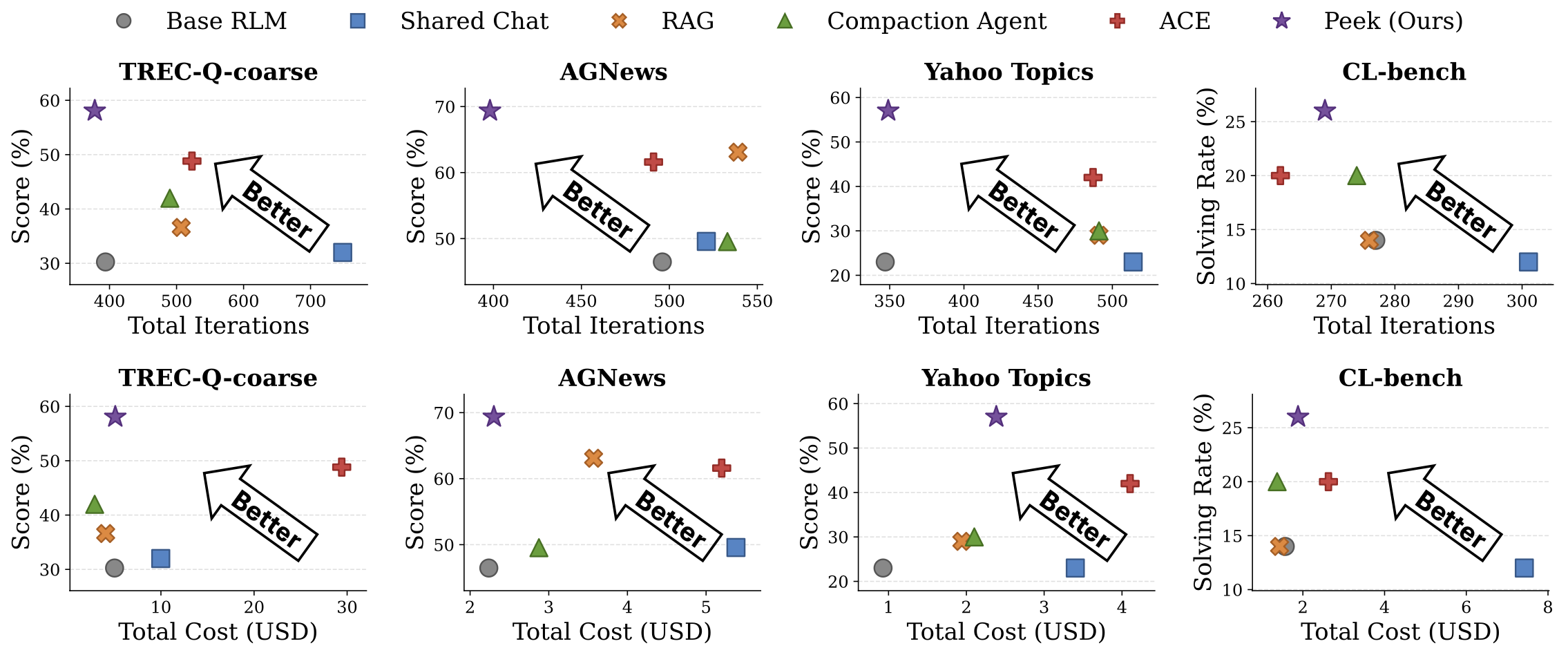
On OOLONG, ACE uses 93 to 145 more iterations than PEEK while scoring lower. On CL-bench, ACE uses the fewest iterations but trails PEEK by +6.0% solving rate and +9.9% rubric accuracy, suggesting that its lower iteration count reflects premature shortcuts rather than better efficiency.
The total-cost view tells the same story. ACE costs 1.7 to 5.8× more than PEEK on OOLONG and 1.4× more on CL-bench while scoring lower. PEEK’s map-maintenance cost is small and predictable, and the improved orientation often reduces enough execution work to offset much of that overhead.
Generalizing Across Models and Agents
The main results use RLM with GPT-5-mini as the base LM, but PEEK is tied to neither RLM nor GPT-5-mini. We also run PEEK with GPT-5.5
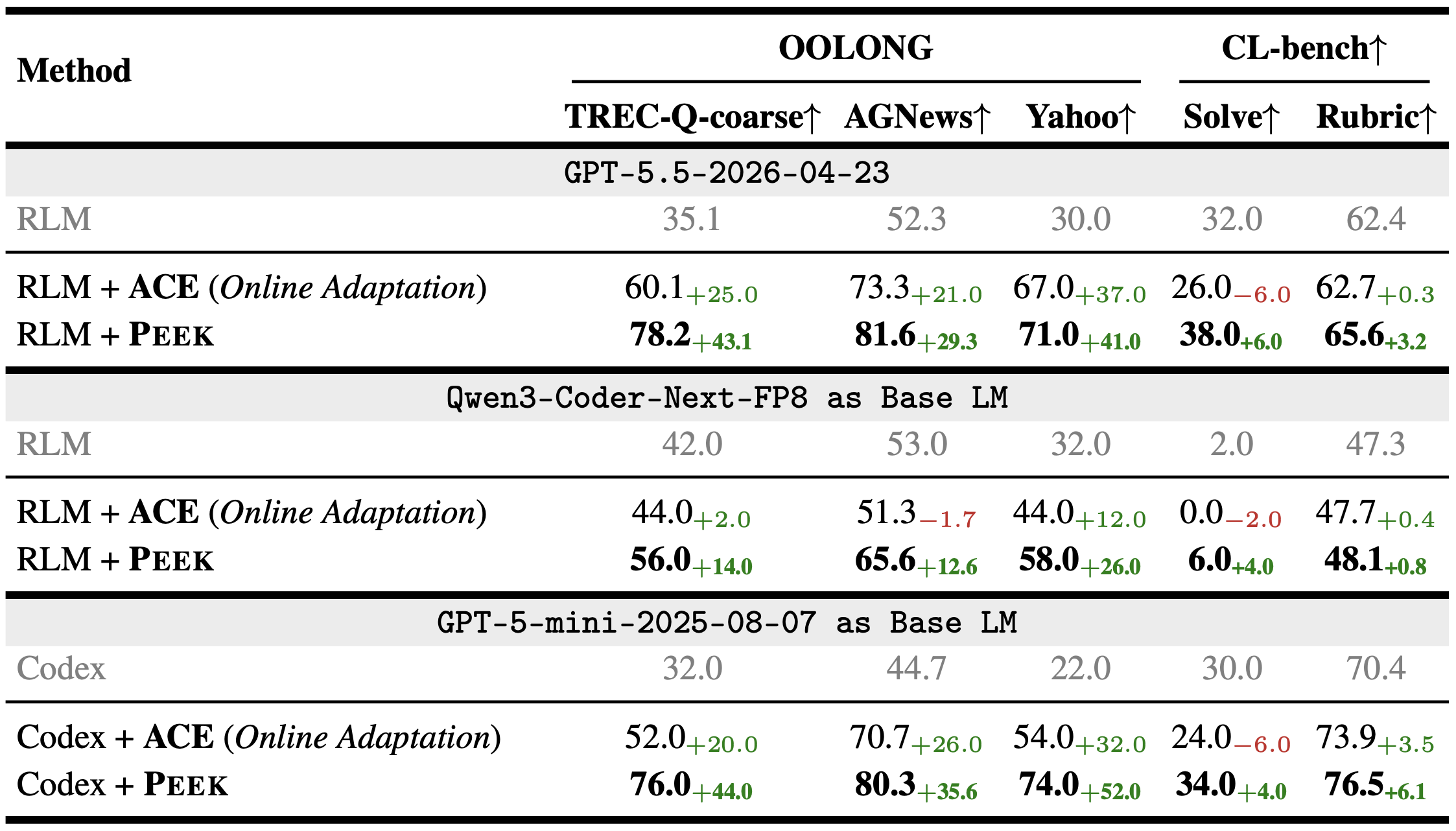
With GPT-5.5, PEEK consistently improves over base RLM and outperforms ACE. With Qwen3-Coder-Next-FP8, it again produces consistent gains. When we switch the backbone agent to Codex, the gains remain and are even larger, suggesting that a context map can help on top of a production-grade coding agent.
Why This Is Not Just a KV Cache
The word “cache” can be confusing here because KV-cache optimization is already an important line of work for improving the serving efficiency of long-context LMs, but it operates at a different layer from PEEK. KV-cache methods optimize the model’s internal key-value states, using techniques such as compression or quantization, token eviction or dropping, reuse across requests or prompts, and offloading or dynamic management, so the same prompt can be served more cheaply or quickly.
PEEK is orthogonal to those model-level optimizations. Instead of reusing or compressing hidden token states, it maintains an agent-level semantic artifact: a bounded context map that records reusable orientation knowledge about a recurring external context. KV-cache methods can make the same agent cheaper or faster to serve, but they do not decide what contextual knowledge should be preserved, updated, or exposed to the agent across tasks. In principle, PEEK can be combined with KV-cache compression, reuse, or offloading to improve serving efficiency further.
What We Tried That Did Not Work
Throughout the project, we kept asking: what should go in a constant-sized map?
We tried several natural alternatives:
- Raw prefix: prepend the first k tokens of the context as the map.
- Sub-goal retrieval: retrieve raw context chunks based on the agent’s latest sub-goal during generation.
- Retrieval-playbook: let an ACE-style playbook evolve across queries, chunk it into 256-token segments, and retrieve the top-4 most query-relevant chunks at inference time.
- Runtime feedback: after each agent root-LM iteration, have an LLM read the trajectory so far, produce natural-language feedback, and replace the map entirely.
- Behavioral instructions: use the map budget for prompt-engineering phrases such as “do not take shortcuts” and “be more goal-oriented.”
On a subset of OOLONG, these variants either produced only modest gains over base RLM (+0.73% for raw prefix, +4.92% for sub-goal retrieval, +0.73% for retrieval-playbook, +5.65% for behavioral instructions) or actively hurt performance (-14.86% for runtime feedback). The common lesson was that the agent does not just need more text in its prompt; it needs a compact, structured, persistent understanding of the context that accumulates across queries and transfers to new tasks.
Conclusion
Impact and Future Work. We view PEEK as opening a broader research agenda on how agents repeatedly interact with persistent long contexts over diverse tasks. Future directions include adaptively adjusting the cache size, training the Distiller, exploring other reusable artifacts, and maintaining collections of caches that agents can interact with through programs or parallel sub-agents.
Limitations. The usefulness of the context map depends on how the agent interacts with the context. If that interaction reveals little reusable knowledge, the map has little to cache. Different agents interact with context differently, so what should be cached may vary across agents.
Long-context agents do not just need bigger windows or better retrievers. They need a place to remember what they have learned about the context itself. PEEK provides that place. A small, persistent, prompt-resident context map, maintained by a programmable cache policy, can deliver substantial gains in quality, iterations, and cost across long-context tasks, across base models, and across agent architectures.
We’re excited to see where the agent-side cache idea goes next. Whether you are a researcher, a developer in this area, or just hacking around, if you enjoyed reading this blog and found it helpful, we would love for you to read the full paper, try PEEK on GitHub on your workloads (don’t forget to ⭐️ star us on GitHub!), or reach out.
Acknowledgements
I would like to thank the wonderful MIT DSG and MIT OASYS labs, my fellow MIT EECS students, and my family for their support during the first year of my PhD. I am also grateful to my friends at UChicago, Stanford, UC Berkeley, Harvard, and Brown for their valuable feedback. We also thank Alex Zhang, the first author of the RLM paper, for insightful discussions.
Citation
BibTeX
To cite this blog post or use PEEK in your research, please use the following citation.
@misc{gu2026peekcontextmaporientation,
title={PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents},
author={Zhuohan Gu and Qizheng Zhang and Omar Khattab and Samuel Madden},
year={2026},
eprint={2605.19932},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.19932},
}